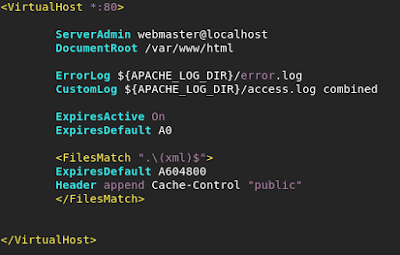
SharpNado - Teaching an old dog evil tricks using .NET Remoting or WCF to host smarter and dynamic payloads
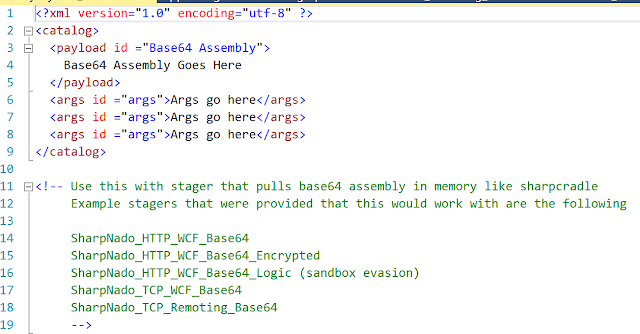
TL;DR: SharpNado is proof of concept tool that demonstrates how one could use .Net Remoting or Windows Communication Foundation (WCF) to host smarter and dynamic .NET payloads. SharpNado is not meant to be a full functioning, robust, payload delivery system nor is it anything groundbreaking. It's merely something to get the creative juices flowing on how one could use these technologies or others to create dynamic and hopefully smarter payloads. I have provided a few simple examples of how this could be used to either dynamically execute base64 assemblies in memory or dynamically compile source code and execute it in memory. This, however, could be expanded upon to include different kinds of stagers, payloads, protocols, etc. So, what is WCF and .NET Remoting? While going over these is beyond the scope of this blog, Microsoft describes Windows Communication Foundation as a framework for building service-oriented applications and .NET Remoting as a framework that allows...